文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
读入文本
1 | import collections |
output:
1 | # sentences 3221 |
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
1 | import collections |
output:
1 | # sentences 3221 |
转载知乎:(https://www.zhihu.com/question/263546637)
疑问:“书上说是从预先知道的分布预测而出现的c误差,既然已经预先知道分布了,那么为什么还有误差呢?”
回答:分布是真实的,但预测的输出只能是一个值,所以会有误差。例如,假设真实世界中90%长头发的人为女性,10%为男性(这是已知的真实分布);此时已知一个人头发长,预测该同学性别。由于只能预测男/女。此时即使你知道真实分布,预测为女,也会有10%的误差。这就是贝叶斯误差。
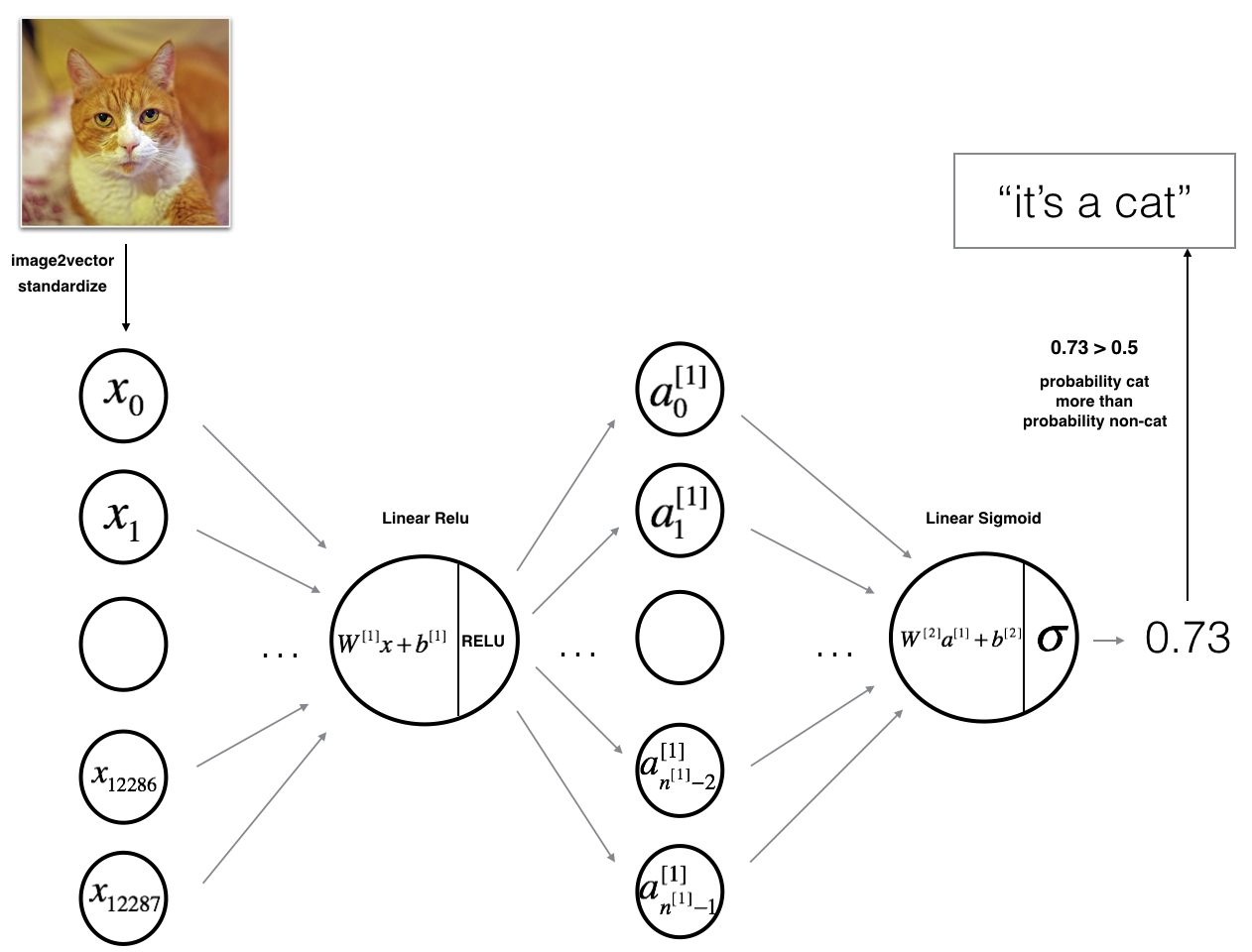
该模型可以概括为: INPUT -> LINEAR -> RELU -> LINEAR -> SIGMOID -> OUTPUT.
然后重复相同的过程。
您将所得向量乘以 ,然后加上截距(偏差)。
最后,取最后一个激活函数为Sigmoid函数,如果大于0.5,则将其分类为猫。
1 | def initialize_parameters(n_x, n_h, n_y): |
在数据分析之前,我们都需要让数据满足一定的规律,达到规范性的要求,便于进行挖掘。
如果不进行变换的话,要不就是维数过多增加了计算成本,要不就是数据过于集中,很难找到数据之间的特征。
在数据变换中,重点是如何将数值进行规范化,有三种常用的规范方法,分别是Min-Max规范化、Z-Score规范化、小数定标规范化。
针对数据库:规范化把关系满足的规范要求分为几级,满足要求最低的是第一范式(1NF),再来是第二范式、第三范式、BC范式和4NF、5NF等等,范数的等级越高,满足的约束集条件越严格。
针对数据:
1.数据的规范化包括归一化标准化正则化,是一个统称(也有人把标准化作为统称)。
2.数据规范化是数据挖掘中的数据变换的一种方式,数据变换将数据变换或统一成适合于数据挖掘的形式,将被挖掘对象的属性数据按比例缩放,使其落入一个小的特定区间内,如[-1, 1]或[0, 1]。
3.对属性值进行规范化常用于涉及神经网络和距离度量的分类算法和聚类算法当中。比如使用神经网络后向传播算法进行分类挖掘时,对训练元组中度量每个属性的输入值进行规范化有利于加快学习阶段的速度。对于基于距离度量相异度的方法,数据归一化能够让所有的属性具有相同的权值。
人工智能(Artificial Intelligence)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。“人工智能是一门极富挑战性的科学,从事这项工作的人必须懂得计算机知识,心理学和哲学。人工智能是包括十分广泛的科学,它由不同的领域组成,如机器学习,计算机视觉等等,人工智能的发展历史是和计算机科学与技术的发展史联系在一起的。除了计算机科学以外, 人工智能还涉及信息论、控制论、自动化、仿生学、生物学、心理学、数理逻辑、语言学、医学和哲学等多门学科。人工智能学科研究的主要内容包括:知识表示、自动推理和搜索方法、机器学习和知识获取、知识处理系统、自然语言理解、计算机视觉、智能机器人、自动程序设计等方面。
Spring Boot 自动配置好了SpringMVC
以下是SpringBoot对SpringMVC的默认配置:(WebMvcAutoConfiguration)
Inclusion of ContentNegotiatingViewResolver and BeanNameViewResolver beans.
Support for serving static resources, including support for WebJars (see below).静态资源文件夹路径,webjars
Static index.html support. 静态首页访问
Custom Favicon support (see below). favicon.ico
自动注册了 of Converter, GenericConverter, Formatter beans.
Formatter 格式化器; 2017.12.17===Date;1 |
|
自己添加的格式化器转换器,我们只需要放在容器中即可
Support for HttpMessageConverters (see below).
HttpMessageConverter:SpringMVC用来转换Http请求和响应的;User—Json;
HttpMessageConverters 是从容器中确定;获取所有的HttpMessageConverter;
自己给容器中添加HttpMessageConverter,只需要将自己的组件注册容器中(@Bean,@Component)
