Numpy
简介:开源的Python科学计算库,方便使用数组、矩阵运算,包含线性代数、傅里叶变换、随机数生成等大量函数。
为什么使用 Numpy?
对于同样的数值计算任务,使用Numpy比直接编写Python代码实现,优点:
- 代码更简洁:Numpy 直接以数组、矩阵为粒度计算并且支持大量的数学函数,而Python需要多层for循环从底层实现;
- 性能更加高效:Numpy的数组存储效率和输入输出计算性能,比Python使用List好很多;
- 注:Numpy的数据存储和Python原生的List是不一样的
- 注:Numpy 的大部分都是C语言实现的,这是Numpy比纯Python代码高效的原因;
Numpy 是 Python各种数据科学类库的基础库:
- 比如SciPy、Scikit-Learn、Tensorflow、PaddlePaddle等
NdarrayObject
1、ndarray用于存储同类型元素的多维数组
2、ndarray中的每个元素在内存中都有相同的存储大小区域
3、 ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
1 | import numpy as np |
创建array的方法
- 从Python的列表List和嵌套列表array
- 使用预定函数arange、ones/ones_like、zeros/zeros_like、emtpy/empty_like、full/full_like、eye等函数创建
- 生成随机数的np.random模块构建
array本身支持的大量操作和函数
- 直接逐元素的加减乘除等算数操作
- 更好的面向多维的数组索引
- 求sum/mean等聚合函数
- 线性代数函数,比如求解逆矩阵、求解方程组
Numpy对数组按索引查询
基础索引、神奇索引、布尔索引
基础索引
一维数组与List操作相似
1 | #二维数组 分别用行坐标和列坐标实现行列筛选 |
注意:Numpy切片修改会修改原数组
神奇索引
用整数数组进行索引
1 | #通过构建列表索引可以筛选数据 |
布尔索引
通过条件可以降维或者查找
1 | X>5#返回true flase 相当于降维 |
random随机函数
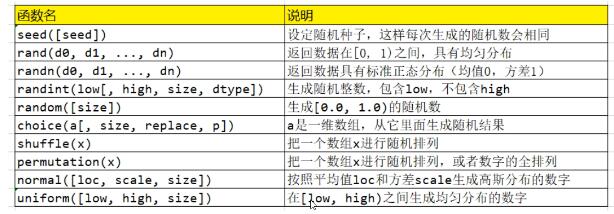
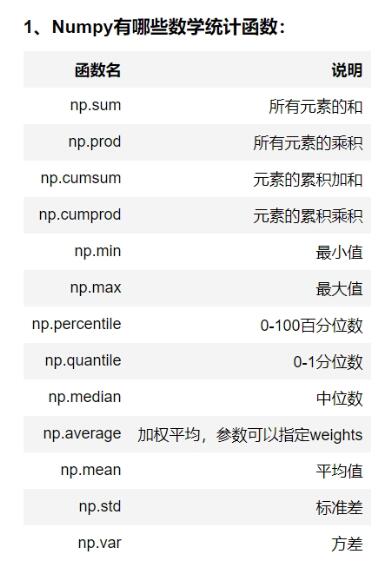
Numpy常用的数字统计函数
实例
Numpy怎样给数组增加一个维度
需要:
在不改变数据的情况下,添加数组维度;(注意观察这个例子,维度变了,但数据不变)原始数组:一维数组arr=[1,2,3,4],其中shape是(4,),取值分别为arr[0],arr[1],arr[2],arr[3]变形数组:二维数组arr[[1,2,3,4]] 其shape是(1,4),取值分别为a[0,0]a[0,1]a[0,2]a[0,3]
实操:
经常需要在纸上手绘数组的形状,来查看不同数组是否形状匹配,是否需要升维和降维
3种方法:
- np.newaxis: 关键字,使用索引和语法给数组添加维度
- np.expand_dims(arr,axis): 方法,和np.newaxis实现一样的功能,给arr在axis位置添加维度
- np.reshape(a,newshape):方法,给一个维度设置为1完成升维
1 | import numpy as np |
方法一:
注意:np.newaxis其实就是None的别名
1 | np.newaxis is None |
所以下方演示中 np.newaxis 可以用 None 替代
1 | #添加一个行维度 |
1 | #添加一个列维度 |
方法二:
np.expand_dims 方法实现的效果,和np.newaxis 关键字是一模一样的
1 | #添加一个行维度 |
1 | #添加一个列维度 |
方法三:
np.reshape 方法
1 | #添加一个行维度 |
Pandas
pandas 是基于NumPy的一种工具, 使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
pandas有两个主要数据结构:Series和DataFrame
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的**数据标签(即索引)**组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
pd.Series(list,index=[]), 第二个参数是Series中数据的索引,可以省略。
- 第一个参数可以是列表 ndarray
1 | import numpy as np,pandas as pd |
- 第一个参数可以是字典,字典的键将作为Series的索引
- 第一个参数可以是DataFrame中的某一行或某一列
Series类型的操作
Series类型索引、切片、运算的操作类似于ndarray,同样的类似Python字典类型的操作,包括保留字in操作、使用.get()方法。
Series和ndarray之间的主要区别在于Series之间的操作会根据索引自动对齐数据。
DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
DataFrame的创建
pd.DataFrame(data,columns = [ ],index = [ ]):columns和index为指定的列、行索引,并按照顺序排列。
- 创建DataFrame最常用的是直接传入一个由等长列表或NumPy数组组成的字典,会自动加上行索引,字典的键会被当做列索引:
1 | import pandas as pd |
如果创建时指定了columns和index索引,则按照索引顺序排列,并且如果传入的列在数据中找不到,就会在结果中产生缺失值:
1 | In [48]: df2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], |
- 另一种常见的创建DataFrame方式是使用嵌套字典,如果嵌套字典传给DataFrame,pandas就会被解释为外层字典的键作为列,内层字典键则作为行索引:
1 | In [65]: pop = {'Nevada': {2001: 2.4, 2002: 2.9}, |

DataFrame对象操作
- df.values:将DataFrame转换为ndarray二维数组,注意后面不加()。
- 通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series。
- 列可以通过赋值的方式进行修改。例如,我们可以给那个空的"debt"列赋上一个标量值或一组值。
- 将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值。
- 为不存在的列赋值会创建出一个新列。关键字del用于删除列。
1 | import pandas as pd |
pandas的基本功能
数据索引:Series和DataFrame的索引是Index类型,Index对象是不可修改,可通过索引值或索引标签获取目标数据,也可通过索引使序列或数据框的计算、操作实现自动化对齐。索引类型index的常用方法:
- .append(idx):连接另一个Index对象,产生新的Index对象
- .diff(idx):计算差集,产生新的Index对象
- .intersection(idx):计算交集
- .union(idx):计算并集
- .delete(loc):删除loc位置处的元素
- .insert(loc,e):在loc位置增加一个元素

重新索引:能够改变、重排Series和DataFrame索引,会创建一个新对象,如果某个索引值当前不存在,就引入缺失值。
df.reindex(index, columns ,fill_value, method, limit, copy ):index/columns为新的行列自定义索引;fill_value为用于填充缺失位置的值;method为填充方法,ffill当前值向前填充,bfill向后填充;limit为最大填充量;copy 默认True,生成新的对象,False时,新旧相等不复制。
1 | In [98]: frame = pd.DataFrame(np.arange(9).reshape((3, 3)), |
删除指定索引:默认返回的是一个新对象。
.drop():能够删除Series和DataFrame指定行或列索引。
删除一行或者一列时,用单引号指定索引,删除多行时用列表指定索引。
如果删除的是列索引,需要增加axis=1或axis='columns’作为参数。
增加inplace=True作为参数,可以就地修改对象,不会返回新的对象。

索引、选取和过滤
df.loc[行标签,列标签]:通过标签查询指定的数据,第一个值为行标签,第二值为列标签。当第二个参数为空时,查询的是单个或多个行的所有列。如果查询多个行、列的话,则两个参数用列表表示。
df.iloc[行位置,列位置]:通过默认生成的数字索引查询指定的数据。
1 | In [128]: data = pd.DataFrame(np.arange(16).reshape((4, 4)), |
在pandas中,有多个方法可以选取和重新组合数据。对于DataFrame,表5-4进行了总结

算术运算:算术运算根据行列索引,对齐后运算,运算默认产生浮点数,对齐时缺项填充NaN (空值)。除了用±*/外,还可以用Series和DataFrame的算术方法,这些方法传入fill_value参数时,可以填充缺省值。比如df1.add(df2, fill_value = 1):
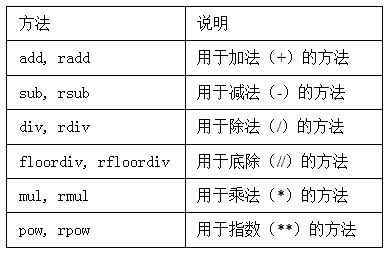
比较运算只能比较相同索引的元素,不进行补齐。采用>< >= <= == !=等符号进行的比较运算,产生布尔值。
排序 :在排序时,任何缺失值默认都会被放到末尾
.sort_index(axis=0, ascending=True):根据指定轴索引的值进行排序。默认轴axis=0, ascending=True,即默认根据0轴的索引值做升序排序。轴axis=1为根据1轴的索引值排序, ascending=False为降序。
在指定轴上根据数值进行排序,默认升序。
Series.sort_values(axis=0, ascending=True):只能根据0轴的值排序。
DataFrame.sort_values(by, axis=0, ascending=True),参数by为axis轴上的某个索引或索引列表。
pandas数据分析
统计分析、相关分析
适用于Series和DataFrame的基本统计分析函数:传入axis='columns’或axis=1将会按行进行运算。
.describe():针对各列的多个统计汇总,用统计学指标快速描述数据的概要。
.sum():计算各列数据的和
.count():非NaN值的数量
.mean( )/.median():计算数据的算术平均值、算术中位数
.var()/.std():计算数据的方差、标准差
.corr()/.cov():计算相关系数矩阵、协方差矩阵,是通过参数对计算出来的。Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵。
.corrwith():利用DataFrame的corrwith方法,可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算),传入一个DataFrame则会计算按列名配对的相关系数。
.min()/.max():计算数据的最小值、最大值
.diff():计算一阶差分,对时间序列很有效
.mode():计算众数,返回频数最高的那(几)个
.mean():计算均值
.quantile():计算分位数(0到1)
.isin():用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集
适用于Series的基本统计分析函数,DataFrame[列名]返回的是一个Series类型。
.unique():返回一个Series中的唯一值组成的数组。
.value_counts():计算一个Series中各值出现的频率。
.argmin()/.argmax():计算数据最大值、最小值所在位置的索引位置(自动索引)
.idxmin()/.idxmax():计算数据最大值、最小值所在位置的索引(自定义索引)
分组
-
DataFrame.groupby():分组函数,使用方法参考https://blog.csdn.net/cymy001/article/details/78300900
-
pandas.cut():根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来进行研究,以揭示其内在的联系和规律性。类似给成绩设定优良中差,比如:0-59分为差,60-70分为中,71-80分为优秀等等。使用方法参考
https://blog.csdn.net/weixin_39541558/article/details/80578529
https://blog.csdn.net/missyougoon/article/details/83986511
pandas读写文本格式的数据
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。下表对它们进行了总结,其中read_csv()、read_table()、to_csv()是用得最多的。

工作中实际碰到的数据可能十分混乱,一些数据加载函数(尤其是read_csv)的参数非常多(read_csv有超过50个参数)。具体使用参考https://seancheney.gitbook.io/python-for-data-analysis-2nd/di-06-zhang-shu-ju-jia-zai-cun-chu-yu-wen-jian-ge-shi
处理缺失数据
在许多数据分析工作中,缺失数据是经常发生的。对于数值数据,pandas使用浮点值NaN(np.nan)表示缺失数据,也可将缺失值表示为NA(Python内置的None值)。
- .info():查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型。
- .isnull():返回一个同样长度的值为布尔型的对象(Series DataFrame),表示哪些值是缺失的,**.notnull()**为其否定形式。
1 | import pandas as pd |
- .dropna():删除缺失数据。对于Series对象,dropna返回一个仅含非空数据和索引值的Series。对于DataFrame对象,dropna默认删除含有缺失值的行;如果想删除含有缺失值的列,需传入axis = 1作为参数;如果想删除全部为缺失值的行或者列,需传入how='all’作为参数;如果想留下一部分缺失数据,需传入thresh = n作为参数,表示每行至少n个非NA值。
1 | import pandas as pd |
- .fillna(value,method,limit,inplace):填充缺失值。value为用于填充的值(比如0、'a’等)或者是字典(比如{‘列’:1,‘列’:8,……}为指定列的缺失数据填充值);method默认值为ffill,向前填充,bfill为向后填充;limit为向前或者向后填充的最大填充量。inplace默认会返回新对象,修改为inplace=True可以对现有对象进行就地修改。
数据转换
替换值
.replace(old, new):用新的数据替换老的数据,如果希望一次性替换多个值,old和new可以是列表。默认会返回一个新的对象,传入inplace=True可以对现有对象进行就地修改。
删除重复数据
- .duplicated():判断各行是否是重复行(前面出现过的行),返回一个布尔型Series。
- .drop_duplicates():删除重复行,返回删除后的DataFrame对象。默认保留的是第一个出现的行,传入keep='last’作为参数后,则保留最后一个出现的行。
- 两者都默认会对全部列做判断,在传入列索引组成的列表[ ‘列1’ , ‘列2’ , ……]作为参数后,可以只对这些列进行重复项判断。
利用函数或字典进行数据转换
- Series.map():接受一个函数或字典作为参数。使用map方法是一种实现元素级转换以及其他数据清理工作的便捷方式。
1 | import pandas as pd |
DataFrame常见函数
df.head():查询数据的前五行
df.tail():查询数据的末尾5行
pandas.cut()
pandas.qcut() 基于分位数的离散化函数。基于秩或基于样本分位数将变量离散化为等大小桶。
pandas.date_range() 返回一个时间索引
df.apply() 沿相应轴应用函数
Series.value_counts() 返回不同数据的计数值
df.aggregate()
df.reset_index() 重新设置index,参数drop = True时会丢弃原来的索引,设置新的从0开始的索引。常与groupby()一起用
numpy.zeros()